منحنی های یادگیری
آموزش 3 نمونه به آسانی خطایی برابر با صفر خواهد داشت زیرا امکان پیدا کردن یک منحنی درجه دو که دقیقا با این سه نقطه برخورد کند همیشه وجود دارد!
-
هرچه مجموعه آموزشی بزرگتر میشود، خطای تابع درجه دو افزایش مییابد.
-
مقدار خطا پس از تعیین اندازه m یا مجموعه آموزشی، ثابت خواهد بود.
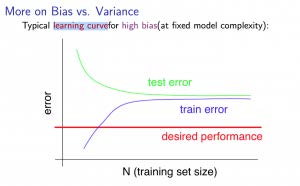
با بایاس زیاد
مجموعه آموزشی کوچک: باعث میشود تا $J_{train}\left ( \Theta \right )$ کم و $J_{cv}\left ( \Theta \right )$ زیاد باشد.
مجموعه آموزشی بزرگ: باعث میشود تا $J_{train}\left ( \Theta \right )$ و $J_{CV}\left ( \Theta \right )$ هر دو مقدار زیادی داشته باشند و $J_{train}\left ( \Theta \right ) \approx J_{CV}\left ( \Theta \right )$
اگر یک الگوریتم با مشکل بایاس زیاد مواجه باشد، اضافه کردن داده آموزشی (به تنهایی) موثر نخواهد بود.
برای مقدار واریانس زیاد، روابط زیر را به لحاظ اندازه مجموعه آموزشی داریم:
با واریانس زیاد
مجموعه آموزشی کوچک: $J_{train}\left ( \Theta \right )$ مقداری کم و $J_{CV}\left ( \Theta \right )$ مقدار زیادی داشته باشد.
مجموعه آموزشی بزرگ: $J_{train}\left ( \Theta \right )$ متناسب با اندازه مجموعه آموزشی افزایش مییابد و $J_{CV}\left ( \Theta \right )$ بدون ثابت شدن کاهش می یابد. همچنین $J_{train}\left ( \Theta \right ) < J_{CV}\left ( \Theta \right )$ خواهد بود و اختلاف قابل توجهی خواهند داشت.
اگر یک الگوریتم با مشکل واریانس زیاد مواجه باشد، داده آموزشی بیشتر احتمالا موثر خواهد بود.
