بهینه سازی هدفمند
ماشین بردار پشتیبان (SVM) یکی دیگر از الگوریتم های یادگیری ماشین با نظارت است که گاهی تمیزتر و قدرتمندتر عمل می کند. اگر به خاطر بیاورید، ما در رگریسیون لجستیک از ضوابط زیر استفاده می کردیم:
$$ if\hspace{0.3cm} y=1,\hspace{0.2cm} then \hspace{0.3cm} h_\theta(x)\approx 1 \hspace{0.3cm} and \hspace{0.3cm}\Theta\ ^ T x \gg 0 $$
$$ if\hspace{0.3cm} y=0,\hspace{0.2cm} then \hspace{0.3cm} h_\theta(x)\approx 0 \hspace{0.3cm} and \hspace{0.3cm}\Theta\ ^ T x \ll 0 $$
تابع هزینه را برای رگریسیون لجستیک (نامنظم) به خاطر بیاورید:
$$ J(\theta) = \frac{1}{m} \sum_{i=1}^m -y^{(i)} \hspace{0.1cm} log(h_\theta(x^{(i)})) - (1 - y^{(i)}) \hspace{0.1cm} log(1 - h_\theta(x^{(i)}) ) $$
$$ = \frac{1}{m} \sum_{i=1}^m -y^{(i)} \hspace{0.1cm} log(\frac{1}{1+e^ {-\theta\ ^ T x^{(i)} }}) - (1 - y^{(i)}) \hspace{0.1cm} log(\frac{1}{1+e^ {-\theta\ ^ T x^{(i)} }} ) $$
برای ساخت ماشین بردار پشتیبان، اولین عبارت تابع هزینه را تغییر می دهیم:
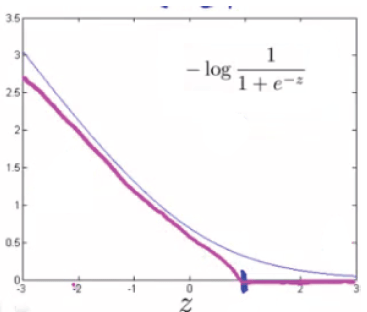
$$ -log(h_\theta(x))=-log(\frac{1}{1+e^ {-\theta\ ^ T x}}) $$
بنابراین هنگامی که $ \theta^{T}x $ (که از این به بعد آن را z می نامیم) بزرگتر از 1 شود، خروجی 0 است. علاوه بر این، برای zهای کوچکتر از 1، به جای منحنی سیگموئید باید از یک خط راست نزولی استفاده کنیم.
(در متون ادبی به آن تابع خطای Hinge می گویند https://en.wikipedia.org/wiki/Hinge_loss)
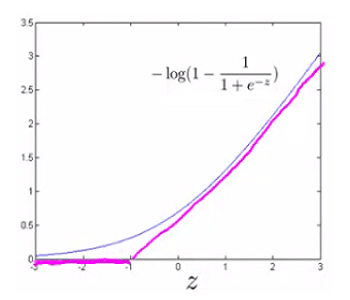
به طور مشابه، عبارت دوم تابع هزینه را تغییر می دهیم:
$$ -log(1- h_\theta(x))=-log(1- \frac{1}{1+e^ {-\theta\ ^ T x }}) $$
بنابراین وقتی که z کمتر از 1- است، خروجی 0 می شود. برای مقادیر بزرگتر از 1- هم آن را تغییر می دهیم و از خط راست صعودی به جای منحنی سیگموئید استفاده می کنیم.
این عبارات نشان دهنده $cost_1 z$ و $cost_0 z$ هستند (به ترتیب، $cost_1 z$ هزینه طبقه بندی برای زمانی که $y=1$ و $cost_0 z$ هزینه طبقه بندی برای $y=0$ است) و ما آن ها را به صورت زیر تعریف می کنیم (k یک ثابت دلخواه است که بزرگی شیب خط را نشان می دهد):
$$ z = \theta^{T} x $$ $$ cost_0(z) = max(0,k(1 + z)) $$ $$ cost_1(z) = max(0,k(1 - z)) $$
عبارت کامل تابع هزینه را در رگریسیون لجستیک (منظم) به یاد بیاورید:
$$ J(\theta) = \frac{1}{m} \sum_{i=1}^m y^{(i)} (-log(h_\theta(x^{(i)}))) + (1 - y^{(i)}) (-log(1 - h_\theta(x^{(i)}) )) + \frac{\lambda}{2m} \sum_{j=1}^n \Theta_j ^ 2 $$
توجه داشته باشید که در معادله بالا علامت منفی در کل عبارت پخش شده است.
ما با جایگزین کردن $cost_0 z$ و $cost_1 z$ در معادله، آن را به تابع هزینه ماشین های بردار پشتیبان تبدیل می کنیم:
$$ J(\theta) = \frac{1}{m} \sum_{i=1}^m y^{(i)} cost_1(\theta^Tx^{(i)}) + (1 - y^{(i)}) \hspace{0.1cm} cost_0(\theta^Tx^{(i)}) + \frac{\lambda}{2m} \sum_{j=1}^n \Theta_j ^ 2 $$
می توانیم با ضرب کردن m در معادله کمی آن را بهینه تر کنیم (بنابراین عامل m در مخرج حذف می شود). توجه داشته باشید که این کار تاثیری در بهینه سازی ما ندارد چون ما یک عدد ثابت مثبت را در معادله ضرب کردیم (برای مثال، مینیمم $(u - 5)^2 + 1$ ، 5 است. با ضرب کردن آن در 10 تبدیل به $10(u - 5)^2 + 10$ می شود که باز هم مینیمم آن 5 است).
$$ J(\theta) = \sum_{i=1}^m y^{(i)} cost_1(\theta^Tx^{(i)}) + (1 - y^{(i)}) \hspace{0.1cm} cost_0(\theta^Tx^{(i)}) + \frac{\lambda}{2} \sum_{j=1}^n \Theta_j ^ 2 $$
به علاوه، طبق قرارداد، ما برای منظم سازی از C به جای $\lambda$ استفاده می کنیم. مانند عبارت زیر:
$$ J(\theta) =C \sum_{i=1}^m y^{(i)} cost_1(\theta^Tx^{(i)}) + (1 - y^{(i)}) \hspace{0.1cm} cost_0(\theta^Tx^{(i)}) + \frac{1}{2} \sum_{j=1}^n \Theta_j ^ 2 $$
این کار مانند این است که معادله را در $C =\frac{1}{\lambda}$ ضرب کنیم بنابراین هنگام بهینه سازی نتیجه تغییر نمی کند. حالا، برای منظم سازی بیشتر (یعنی کاهش overfitting)، C را کاهش می دهیم و زمانی که بخواهیم کم تر منظم سازی کنیم (یعنی کاهش underfitting)، C را افزایش می دهیم.
در نهایت، توجه داشته باشید که معادله فرضی ماشین بردار پشتیبان احتمال 0 یا 1 بودن y را نشان نمی دهد (مانند چیزی که در معادله فرضی رگریسیون لجستیک داشتیم). در عوض، خروجی آن 0 یا 1 است. (اگر بخواهیم به طور تخصصی صحبت کنیم، این یک تابع تفکیکی است.)
$$ h_\theta(x)= \begin{cases} 1 & if \hspace{0.3cm} \Theta^T x\ge 0\newline 0 & otherwise \end{cases} $$