فرضیه غیر خطی
انجام رگرسیون لجستیک با مجموعه ای پیچیده از داده ها و ویژگی های زیاد، کار بسیار دشواری است. تصور کنید فرضیه ای با ۳ ویژگی دارید به همراه تمام جملات درجه ۲ آن:
$$ g(\theta_0 + \theta_1 x_1^2 + \theta_2 x_1 x_2 + \theta_3 x_1 x_3 + \theta_4 x_2 ^2 + \theta_5 x_2 x_3 + \theta_6 x_3 ^2 ) $$ میبینیم که ۶ ویژگی به ما میدهد.
روشی دقیق برای محاسبه تعداد ویژگی ها: $ \frac{(n + r - 1)!}{r!(n-1)!} $
که برای مثال بالا به این صورت خواهد بود: $ \frac{(3 + 2 - 1)!}{2!(3-1)!} = \frac{4!}{4} = 6 $
برای ۱۰۰ ویژگی اگر بخواهیم آن ها را درجه ۲ کنیم، خواهیم داشت: $ \frac{(100 + 2 - 1)!}{2!(100-1)!} = 5050 $ ویژگی جدید.
ما میتوانیم رشد تعداد ویژگی هایی را که با تمام جملات درجه ۲ به دست میآوریم را به صورت $ O(\frac{n^2}{2}) $ تقریب کنیم. و اگر بخواهیم تمام جملات درجه ۳ را در فرضیه خود داشته باشیم، ویژگی ها به صورت مرتبه زمانی $ O(n^3) $ رشد میکنند.
میبینیم که با افزایش تعداد ویژگی های ما، تعداد ویژگی های درجه ۲ و یا درجه ۳ به سرعت افزایش مییابند
مثال:
تصور کنید که داده های شما مجموعه ای از عکس های $50 \times 50$ پیکسل سیاه سفید هستند، و هدف شما طبقه بندی است برای اینکه متوجه بشویم کدام یک از آن ها ماشین است. تعداد ویژگی های ما اگر هر جفت پیکسل را با هم مقایسه کنیم برابر است با: $2500$ و اگر عکس های ما به جای سیاه سفید بودن RGB باشند تعداد ویژگی ها برابر خواهد بود با: $ 7500 $
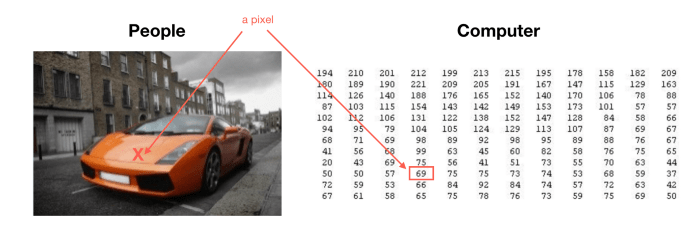
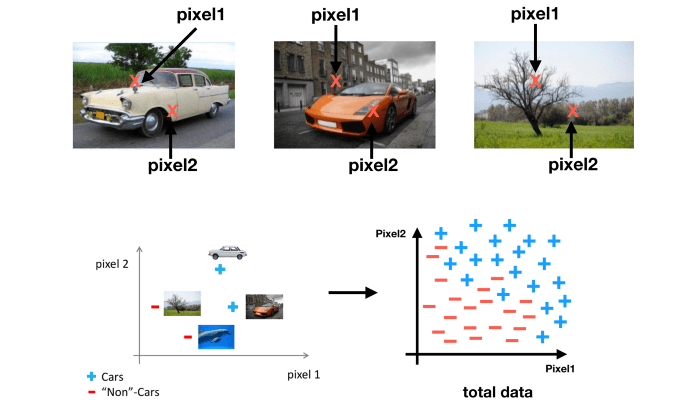
حالا تصور کنید که باید یک تابع فرضیه درجه ۲ بسازیم، که تعداد کد ویژگی های ما در حدود $ \frac{2500^2}{2} = 3125000 $ خواهد بود!
که بسیار غیر عملی است.
شبکه های عصبی راه دیگری را برای انجام مسائل یادگیری ماشین ارائه میدهد، زمانی که ما فرضیه ای پیچیده با تعداد زیادی ویژگی داریم!