تابع هزینه در Overfitting
اگر تابع فرضیه ما مشکل overfitting دارد، ما میتوانیم وزن بعضی از بخش های تابع فرضیه را با افزایش هزینه آن ها کاهش دهیم:
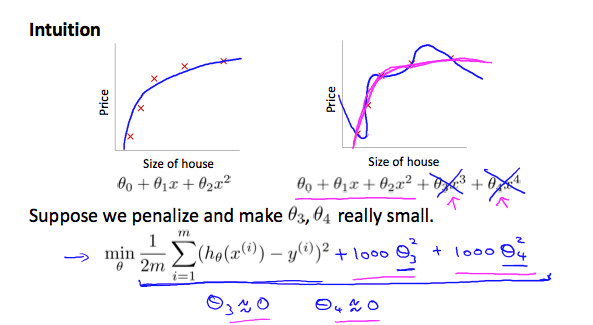
تصور کنید که تابع زیر را درجه دو تر کنیم: $$ \theta_0 + \theta_1x + \theta_2 x^2 + \theta_3 x^3 +\theta_4 x^4 $$
ما میخواهیم تاثیر $\theta_3 x^3$ و $\theta_4 x^4$ را از بین ببریم ، بدون اینکه از شر این ویژگی ها خلاص شویم یا فرم تابع فرضیه خود را تغییر دهیم، ما میتوانیم تابع هزینه خود را اصلاح کنیم:
$$ min_\theta \frac{1}{2m} \sum_{i = 1}^m (h_\theta(x^{(i)}) - y^{(i)})^2 + 1000 \cdot \theta_3 ^2 + 1000 \cdot \theta_4 ^ 2 $$
ما اینجا در انتها دو بخش اضافه کرده ایم تا هزینه $\theta_3$ و $\theta_4$ را افزایش دهیم. حالا برای اینکه تابع هزینه به صفر نزدیک شود، ما باید مقادیر $\theta_3$ و $\theta_4$ را به صفر نزدیک کنیم.
این کار به خوبی مقادیر $\theta_3 x^3$ و $\theta_4 x^4$ را در تابع هزینه ما کاهش میهد.
در نتیجه میبینیم که فرضیه جدید (که توسط منحنی صورتی نشان داده شده است) مانند یک تابع درجه دوم به نظر میرسد، و به خاطر اصلاحات در $\theta_3 x^3$ و $\theta_4 x^4$ با داده ها تناسب بهتری دارد.
و برای جمع بندی میتوانیم بنویسیم: $$ min_\theta \frac{1}{2m} \sum_{i = 1}^m (h_\theta(x^{(i)}) - y^{(i)})^2 + \lambda \sum_{j = 1}^n \theta_j ^ 2 $$
لامبدا ($\lambda$) پارامتر منظم سازی (regularization parameter) است، تعیین میکند که هزینه پارامتر های تتا ما چه قدر باید زیاد شود.
با استفاده از تابع هزینه بالا ما میتوانیم خروجی تابع فرضیه خود را صافکاری کنیم تا وضعیت overfitting را کاهش دهیم.
اگر پارامتر لامبدا بسیار بزرگ انتخاب شود، ممکن است تابع ما را بیش از حد صافکاری کند و باعث underfitting شود!