طبقه بندی چند کلاسه
هنگامی که در طبقه بندی، بیش از دو دسته داشته باشیم به جای $y = \text{ {0,1} }$ تعاریف خود را به $ y = \text { {0,1, …, n} } $ گسترش میدهیم.
از آنجا که ما مسئله خودمان را به n+1 (n+1 به این خاطر که ایندکس از صفر شروع میشود) مسئله طبقه بندی باینری تقسیم میکنیم، در هر کدام از آن ها ما احتمال عضویت $y$ را در یکی از کلاس هایمان پیش بینی میکنیم:
$$ \begin{align*}& y \in \lbrace0, 1 … n\rbrace \newline& h_\theta^{(0)}(x) = P(y = 0 | x ; \theta) \newline& h_\theta^{(1)}(x) = P(y = 1 | x ; \theta) \newline& \cdots \newline& h_\theta^{(n)}(x) = P(y = n | x ; \theta) \newline& \mathrm{prediction} = \max_i( h_\theta ^{(i)}(x) )\newline\end{align*} $$
ما در واقع یک کلاس را انتخاب میکنیم و سپس بقیه را به یک کلاس دوم واحد تبدیل میکنیم، این کار را به طور مکرر انجام میدهیم ، و binary logistic regression برای هر کدام از آن ها به کار میبریم، و سپس از تابع فرضیه ای برای پیش بینی استفاده میکنیم که بالاترین مقدار را برگرداننده باشد.
تصویر زیر نحوه طبقه بندی 3 کلاس را نشان میدهد:
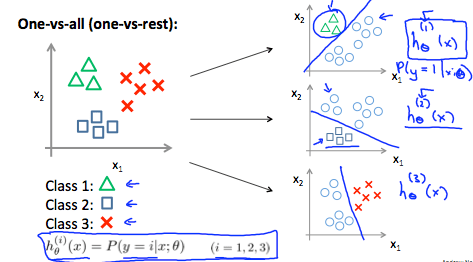
به طور خلاصه:
برای هر $class \text{ } i$ تابع فرضیه logistic regression classifier را برای پیشبینی احتمال $y=i$ تشکیل بدهید.
و برای یک ورودی جدید به اسم $x$ ، $i$ امین کلاسی که ماکسیمم است را انتخاب کنید:
$$ \max_i ( h_\theta^{(i)} (x) ) $$