Putting It Together
2 دقیقه | 2020/10/11
ابتدا معماری شبکه خود را انتخاب کنید!
لایه های شبکه عصبی خود را انتخاب کنید، از جمله اینکه چند گره پنهان در هر لایه و در کل چند لایه میخواهد داشته باشید.
- تعداد گره های ورودی = ابعاد ویژگی های $x^{(i)}$
- تعداد گره های خروجی = تعداد کلاس ها (طبقه بندی ها)
- تعداد گره های پنهان در هر لایه = معمولا هر چه بیشتر بهتر (افزایش تعداد گره های پنهان باید با هزینه محاسبه آن ها تعادل داشته باشد)
- پیش فرض ها: ۱ لایه پنهان، اگر بیش از ۱ لایه پنهان دارید پیشنهاد میشود که در هر لایه پنهان تعداد گره یکسانی داشته باشید.
آموزش یک شبکه عصبی
- مقدار دهی اولیه تصادفی وزن ها
- برای پیاده سازی انتشار به جلو، محاسبه $h_\Theta(x ^{(i)})$ برای هر $x ^{(i)}$
- پیاده سازی تابع هزینه
- پیاده سازی پس انتشار برای محاسبه مشتقات جزئی
- استفاده از بررسی گرادیان برای اینکه مطمئن شویم پس انتشار کار میکند، و بعد از آن توقف بررسی گرادیان.
- استفاده از گرادیان کاهشی یا یک تابع توکار بهینه سازی برای به حداقل برساندن تابع هزینه با استفاده از وزن های داخل تتا
هنگام استفاده از انتشار به جلو و پس انتشار در هر نمونه آموزشی حلقه میزنیم:
,for i = 1:m
Perform forward propagation and backpropagation using example (x(i),y(i))
Get activations a(l) and delta terms d(l) for l = 2,...,L
تصویر زیر به ما شهودی از آنچه که در حین پیاده سازی شبکه عصبی اتفاق میافتد میدهد:
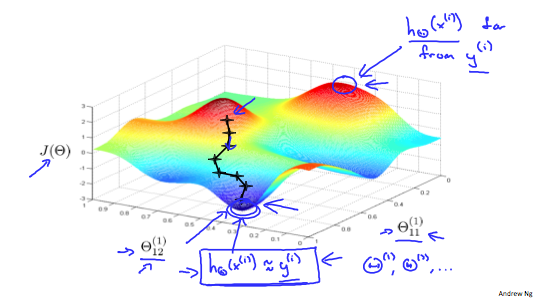
در حالت ایده آل، میخواهیم: $$ h_\Theta (x^{(i)}) \approx y^{(i)} $$
که این یعنی تابع هزینه ما به حداقل میرسد، اما به خاطر داشته باشید که $J(\Theta)$ محدب نیست، که بنابراین میتوانیم به جای آن در مینیمم محلی قرار بگیریم.