یادگیری بدون نظارت چیست؟
1 دقیقه | 2020/09/06
تعریف یادگیری بدون نظارت
یادگیری بدون نظارت این امکان را به ما مـیدهد کــه بدون داشتن هیچ ایده ای نسبت به خروجی داده ها به حل مشکلات نزدیک شویم. در واقع در اینجا داده های ما هیچ برچسبی نـدارنـد و الگوریتمها به حال خود رها میشوند تا سـاختـارهــای موجود در میان دادهها را کشف کنند. مسائل بدون نظارت ها به دو دسته خوشه بندی و غیر خوشه بندی تقسیم میشوند.
خوشه بندی
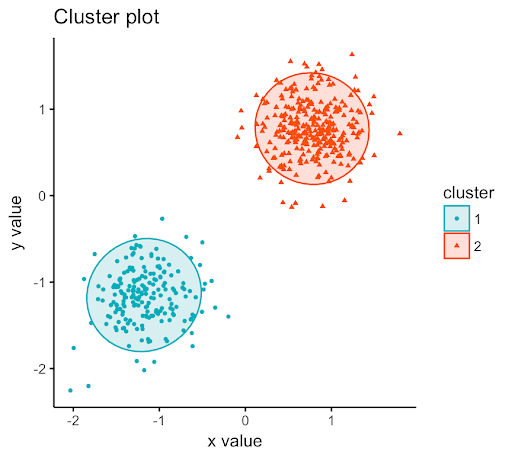
در این مسـائـــل سـعــی مـیکــنیم داده هایی با ویژگی های مشترک را به چـندین گــروه تقـسیم کــنیم، یعنی آن ها را به خوشه ها تخصیص بدهیم. فرض کنید مجموعه داده از 1000000 ژن مختلف دارید و میخواهید راهی پیدا کنید که به صورت خودکار آن ها را گروه بندی کند که به نوعی به هم شباهت دارند.
مثال های بیشتر …
- دسته بندی مشتری های فروشگاه اینترنتی تا بتوانیم مشتری های مشابه را در یک خوشه نگه داری کنیم.
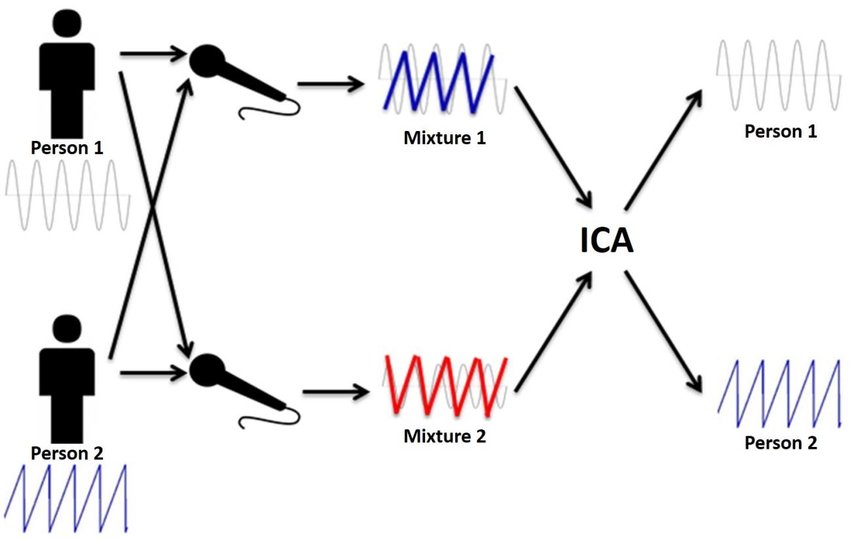
- الگوریتم Cocktail Party به شما امکان میدهد کـــه در مــحیط بــی نظم سـاختـار پیدا کنید: