منظم سازی و بایاس/واریانس
در ادامه به جای بررسی d و تاثیر آن بر بایاس/واریانس، نگاهی به پارامتر مرتب سازی $\lambda$ خواهیم داشت.
- $\lambda$ بزرگ: بایاس زیاد (underfitting)
- $\lambda$ متوسط: مقدار مناسب
- $\lambda$ کوچک: واریانس زیاد (overfitting)
$\lambda$ بزرگ به شدت در تمامی پارامترهای $\theta$ ایجاد نقص میکند که این مسئله خط تابع حاصل شده را بسیار ساده کرده و موجب underfitting خواهد شد.
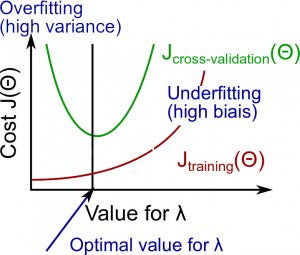
رابطه $\lambda$ با مجموعه آموزشی و مجموعه واریانس به صورت زیر است:
$\lambda$ کوچک: $J_{train}(\Theta )$ کم و $J_{CV}(\Theta )$ مقدار زیادی خواهد داشت (واریانس زیاد/overfitting).
$\lambda$ متوسط: مقدار $J_{train}(\Theta )$ و $J_{CV}(\Theta )$ تا حدودی کم خواهد بود و $J_{train}(\Theta ) \approx J_{CV}(\Theta )$.
$\lambda$ بزرگ: هر دو مقدار $J_{train}(\Theta )$ و $J_{CV}(\Theta )$ زیاد خواهد بود (بایاس زیاد/underfitting).
تصویر زیر رابطه بین $\lambda$ و فرضیه را ترسیم میکند:
برای انتخاب مدل و مقدار $\lambda$ در منظم سازی، نیاز داریم که:
- لیستی از مقادیر $\lambda$ ایجاد کنید، برای مثال:
$$\lambda \in { 0,0.01,0.02,0.04,0.08,0.16,0.32,0.64,1.28,2.56,5.12,10.24 } $$
-
مجموعه ای از مدل ها با درجه های متفاوت یا هر تفاوت دیگری بسازید.
-
بر روی مقادیر $\lambda$ پیمایش کنید و برای هر $\lambda$ تمامی مدل ها را تا یادگیری چند $\Theta$ طی کنید.
-
خطای cross validation را با کمک $\Theta$ آموخته شده، روی $J_{cv}\left ( \Theta \right )$، و بدون منظم سازی یا $\lambda = 0$ محاسبه کنید.
-
بهترین ترکیب که کمترین خطا را روی مجموعه cross validation تولید میکند انتخاب کنید.
-
با استفاده از بهترین ترکیب $\Theta$ و $\lambda$، این ترکیب را روی $J_{test}\left ( \Theta \right )$ پیاده کرده تا اطمینان حاصل کنید از اینکه آیا مسئله به خوبی قابل تعمیم است یا خیر.