ارائه مدل قسمت اول
چگونه یک تابع فرضیه را با استفاده از شبکه های عصبی نشان خواهیم داد؟
شبکه های عصبی به عنوان روشی برای شبیه سازی نورون ها یا شبکه ای از نورون های در مغز ساخته شده اند.
یک نورون در مغز به این شکل است:
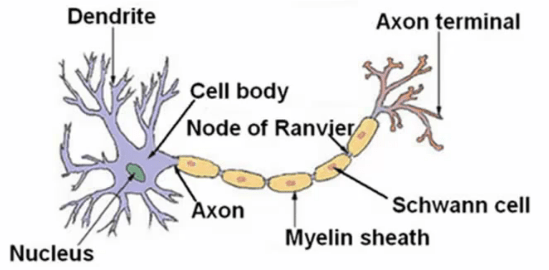
که به طور کلی از سه بخش قابل توجه زیر ساخته شده است:
- بدنه سلول
- بخش ورودی دنریت
- بخش خروجی اکسون
به طور ساده میتوانیم بگوییم که:
نورون ها اساسا واحد های محاسباتی هستند که از طریق رشته سیم های دنریت پالس های الکتریکی به اسم اسپایک را ورودی میگیرند، و آن ها را به خروجی یا همان اکسون هدایت میکنند. بنابراین متوجه میشویم که نورون ها توسط پالس های الکتریکی با هم ارتباط برقرار میکنند.
در شبکه های عصبی مصنوعی، نورون ها واحد هایی لجستیکی هستند:
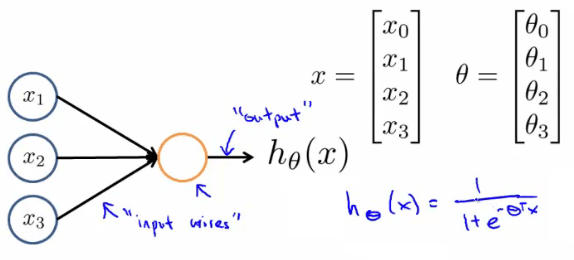
در مدل ما دنریت ها شبیه به ویژگی ها ورودی $x_1 … x_n$ هستند، و خروجی ما تابع فرضیه است.
در این مدل گره ورودی $x_0$ واحد بایاس یا نام دارد که همیشه برابر با مقدار ۱ است. در شبکه های عصبی ما از تابع لجستیکی که در طبقه بندی داشتیم استفاده میکنیم: $$ \frac{1}{1+e^{- \theta^T x}} $$ اگر چه که در شبکه های عصبی گاهی اوقات آن را تابع فعال سازی سیگموئید صدا میزنیم، بردار $\theta$ نیز weights یا وزن های مدل نامیده میشوند.
به طور ساده میتوانیم به این شکل نمایش دهیم:
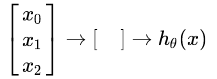
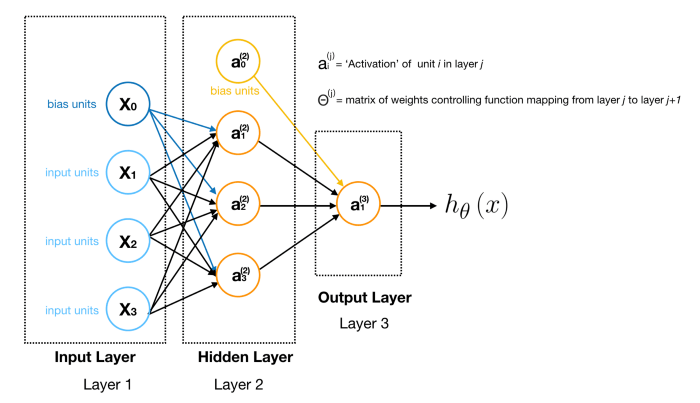
گره های ورودی یا لایه اول داخل لایه دوم میشوند، و خروجی هم تابع فرضیه است. لایه اول را لایه ورودی مینامیم، و لایه دوم را هم لایه خروجی مینامیم، که تابع فرضیه را به عنوان خروجی نتیجه میدهد.
ما میتوانیم لایه های میانی از گره ها داشته باشیم که بین لایه ورودی و خروجی قرار میگیرند، که به آن ها لایه های پنهان میگوییم.
ما گره های لایه های میانی یا پنهان را به صورت $a_0 ^2 … a_n ^2$ نام گذاری میکنیم، و به آن ها واحد های فعال سازی میگوییم.
$$ \begin{align*}& a_i^{(j)} = \text{“activation” of unit $i$ in layer $j$} \newline& \Theta^{(j)} = \text{matrix of weights controlling function mapping from layer $j$ to layer $j+1$}\end{align*} $$
به طور مثال اگر فقط یک لایه پنهان داشته باشیم به این شکل میشود:
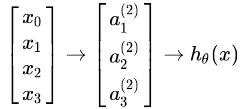
مقدار هر گره فعال ساز به صورت زیر به دست میآید:
$$ \begin{align*} a_1^{(2)} = g(\Theta_{10}^{(1)}x_0 + \Theta_{11}^{(1)}x_1 + \Theta_{12}^{(1)}x_2 + \Theta_{13}^{(1)}x_3) \newline a_2^{(2)} = g(\Theta_{20}^{(1)}x_0 + \Theta_{21}^{(1)}x_1 + \Theta_{22}^{(1)}x_2 + \Theta_{23}^{(1)}x_3) \newline a_3^{(2)} = g(\Theta_{30}^{(1)}x_0 + \Theta_{31}^{(1)}x_1 + \Theta_{32}^{(1)}x_2 + \Theta_{33}^{(1)}x_3) \newline h_\Theta(x) = a_1^{(3)} = g(\Theta_{10}^{(2)}a_0^{(2)} + \Theta_{11}^{(2)}a_1^{(2)} + \Theta_{12}^{(2)}a_2^{(2)} + \Theta_{13}^{(2)}a_3^{(2)}) \newline \end{align*} $$
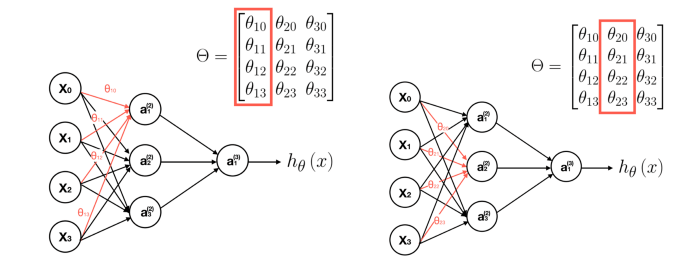
این به ما میگوید که گره های فعال ساز مان را با استفاده از یک ماتریس $3 \times 4$ از پارامتر ها محاسبه میکنیم. به این ترتیب که ما هر ردیف (row) از پارامتر ها را به ورودی های خود اعمال میکنیم، تا مقدار یک گره فعال ساز را بدست آوریم.
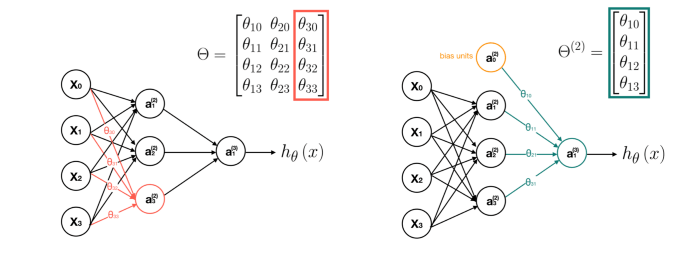
و خروجی فرضیه ما تابعی لجستیکی است که روی مجموع مقادیر گره های فعال ساز ما اعمال میشود، که در ماتریسی از پارامتر های دیگری ($\Theta^{(2)}$) ضرب میشود.
محاسبه $a_1 ^{(2)}$ :
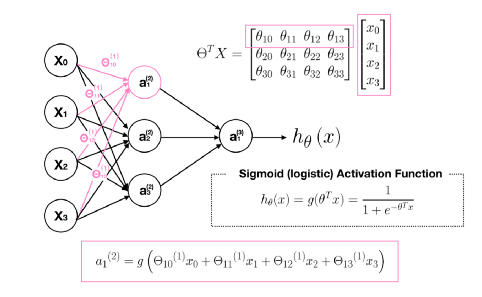
محاسبه $a_2 ^{(2)}$ :
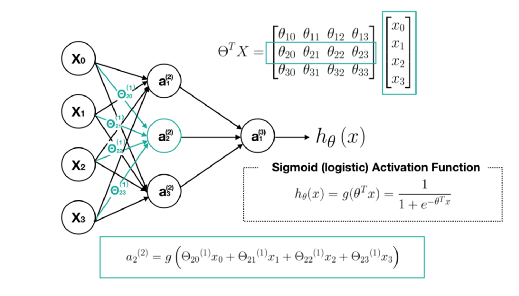
محاسبه $a_3 ^{(2)}$ :
[تصحیح: ردیف سوم از ماتریس $\Theta^T X$ باید انتخاب شود]
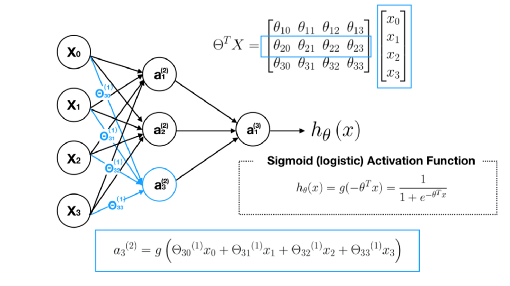
محاسبه $a_1 ^{(3)}$ یا همان $h_\Theta(x)$:
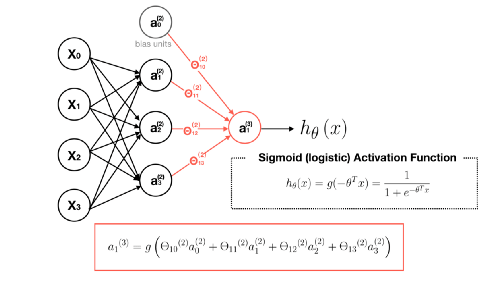
$\Theta^{(2)}$ شامل وزن های گره های لایه دوم است.
به طور کلی هر لابه ماتریس وزن خود را دارد که به شکل $ \Theta^{(j)} $ نام گذاری میشود.
ابعاد این ماتریس های وزنی به شکل زیر محاسبه میشوند:
اگر شبکه ما شامل $s_j$ واحد در هر لایه $j$ است، و $s_{j+1}$ واحد داخل لایه $j+1$ ام است، سپس ابعاد ماتریس $\Theta^{(j)}$ برابر با $ s_{j+1} \times (s_j + 1) $ خواهد بود.
1+ آورده شده به خاطر گره بایاس است. گره بایاس در گره های خروجی شامل نمیشود، اما در گره های ورودی وجود دارد.
مثال:
اگر لایه اول ۲ گره ورودی، و لایه دوم ۴ گره فعال ساز داشته باشد، ابعاد $\Theta^{(1)}$ به صورت $4 \times 3$ خواهد بود، به طوری که:
$$ s_j = 2, s_{j+1} = 4 $$
$$ s_{j+1} \times (s_j + 1) = 4 \times 3 $$